
























Ansys优势杂志
日期:2020年
弹性计算和大数据分析解决物理验证的复杂性
作者:Nitin Navale,美国圣何塞Xilinx CAD经理

更大、更复杂的硅设计使验证方法变得紧张,并减缓了结果和上市的时间。Xilinx的工程师希望利用大数据分析来简化他们在尖端芯片上的验证流程,他们向Ansys寻求答案。
当今许多快速发展的应用——无论是人工智能、自动驾驶汽车、基础设施还是高性能计算(HPC)——都依赖于前沿的现场可编程门阵列(fpga)的性能和灵活性。华体会官网app下载新浪

Xilinx XCVU440可以包含多达400个fabric子区域(FSR)实例,每个实例最多有5,000个IP块实例。
硅设计趋势——以及随之而来的要求更高性能和功能的压力——逆流而上,又回到了Xilinx的工程师身上。Xilinx是一家拥有35年历史的老牌硅谷公司,发明了现场可编程性。由于其独特的可编程架构,fpga一直是相对于标准集成电路或定制的片上系统(soc)更大的设备,最近该公司的Versal ACAP产品上的新功能的爆发只会使它们更大、更复杂。
此外,超低电压导致极薄的噪声边际,因此变异性可能很严重。这会影响时序,其中时序延迟变化作为电压的函数随每个节点而变化。
由于拥有数十亿个实例和晶体管,这些FPGA设计需要更高的容量和足够的规模和覆盖范围(比传统的动态分析和静态签出方法多50倍)来进行适当的时序分析。如果工具容量已经有限,团队通常没有预算或上市时间来承担运行更长的模拟或更多的模拟周期以获得适当的覆盖。
其他需要考虑的问题包括2.5D和3D封装路由和技术的复杂性,如芯片-晶圆-基板(CoWoS),鳍场效应晶体管(finfet)的老化诱导应力,以及热和焦耳加热。此外,设计人员需要一起建模芯片,封装和系统,以确保一个健全的整体电力输送网络。
与复杂性搏斗
面对这种复杂性,Xilinx团队已经适应了这些验证挑战。该公司采用了大数据分析和弹性计算功能,由Ansys提供支持,加快了设计的完成速度,同时准确地涵盖了芯片上可能存在显著差异的多物理场问题。
该公司的最新产品之一是Xilinx XCVU440,它包含3000万个ASIC门。该系列的任何产品都可以包含多达400个fabric子区域(FSR)实例,每个实例最多具有5,000个IP块实例。(FSR是全芯片之下的第二大构件。)IP块本质上是异构的-自定义,半自定义,数字和混合信号。
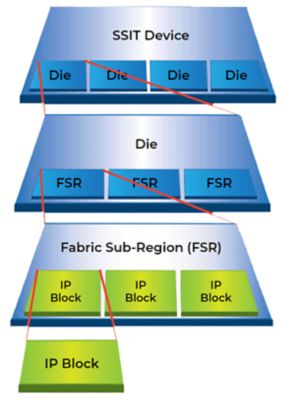
硅互连技术装置在硅中间体上包含多个模具。单个模具可以包含100到400个织物子区域(FSR)实例。FSR通常有2500 ~ 5000个IP块实例。
Xilinx在静态时间分析(STA)方面并不缺乏经验,但是随着在更精细的过程节点上的特征复杂性越来越大,现代的STA正成为一个越来越大的挑战。该公司需要精确的电源电压建模和更广泛的覆盖范围。由于单个芯片上有数十亿个实例和晶体管,工程师们需要一个能够在足够覆盖范围内扩展的解决方案提供更高的容量。
传统上,为了在子区域上执行STA,设计师会将整个芯片加载到不需要他们注意的工具和黑盒区域中。但事实证明,分离或修剪部分设计来进行STA越来越困难,使用传统方法进行扩展已经开始失效。甚至黑盒ip也会消耗内存并影响工具性能!传统方法最适用于实例很少的大块,XCVU440不是那种野兽。
相反,该团队研究了一种子系统方法,该方法可以简化STA挑战,并在不影响准确性的情况下加快得到结果的时间。他们选择利用Ansys SeaScape,这是一个专门构建的大数据平台,提供弹性计算功能和分布式文件/数据服务。SeaScape可以处理大型设计,并在更小的cpu和更小的内存占用上有效地将它们分布到整个计算场。从这个平台上,他们能够加载芯片,并对其进行精简,从而创建一个用于STA分析的虚拟设计,该设计仅由整个设备的最相关方面组成。
随着模拟数据规模越来越大,Xilinx利用Ansys SeaScape及其map-reduce分析来精简芯片规模的设计,以实现更快的时序分析。
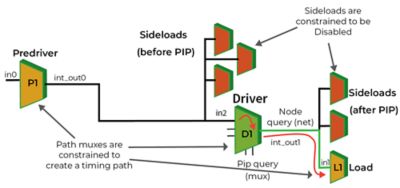
Xilinx有一个名为“定时捕获”(Timing Capture)的内部流程,它不仅需要芯片的物理视图,还需要对其点对点互连延迟的感知。而不是整个设计的定时,定时捕获专注于高度关键的互连路径的子集。
利用ANSYS Seascape进行大型设计缩放进行时序分析
设计团队首先将整个芯片作为一个抽象的物理视图加载到SeaScape中——用于芯片级块的是DEF和SPEF(设计交换格式,标准寄生交换格式),用于IP块的是LEF(库交换格式)——然后将其精简为只包含下游分析所需的精确IP实例列表。在SeaScape中,他们可以很容易地删除不需要的IP实例,然后删除任何闲置的网络。为了确保电容负载不丢失,所有悬挂耦合帽都连接到虚拟攻击器上。最终的视图在原始芯片的基础上缩小了范围,包含了分析所需的精确IP实例,而不损失精度。
从那里,团队可以导出修剪过的Verilog、DEF和SPEF视图,这些视图可以加载到其他分析中。
随着模拟数据规模越来越大,Xilinx利用Ansys SeaScape及其map-reduce分析来精简芯片规模的设计,以实现更快的时序分析。
Xilinx在一个“迷你soc”上使用一个FSR进行了一个实验,其中包含大约375,000个块实例。如果团队没有过滤它,而是按原样运行纯FSR,他们的STA计时器将无法处理它的大小。这项修剪工作由Ansys SeaScape无缝管理,只需要40名SeaScape工人,运行时间为6.5小时。然后STA能够处理修剪设计在一个非常可观的12小时每个角落(挂钟时间)。有趣的是,通过Ansys Path FX进行同样的设计,每个角落的运行时间仅为1小时(使用一个主许可证和42个工人)。
然后,该团队在一个中等规模的多fsr实验(33个fsr和3200万个块实例)上运行了相同的测试。和以前一样,STA无法完成未修剪的设计。修剪后,STA现在完成了每个角落的挂钟时间为四天。再一次,Path FX的一天周转速度更快。
该团队所完成的是采用一个接近全芯片的设计版本,将其精简以适合STA工具,并在合理的时间内实现退出。
ANSYS RedHawk-SC:未来友好的全芯片EM/IR SignOff
与此同时,Xilinx的另一个团队正在使用Ansys RedHawk-SC进行EM/IR签收,以了解该工具如何在相同的全芯片规模上处理复杂性和规模。EM/IR签收的目标是将芯片划分为可以在1-2 TB主机上处理的东西,并在夜间运行,最好在8小时以内。
为了更好地把握后期技术节点设计复杂性的增加,可以使用Xilinx的16 nm UltraScale+设计作为参考点。该团队通过将整个芯片划分为七个分区来签署EM/IR,初始设置大约需要一个人一个月的时间。使用ecoo的迭代重播大约需要一个人每周来覆盖整个芯片。为了实现相同的工具容量和分析吞吐量,7纳米的Versal芯片需要40个分区和5倍的工程人员小时才能在相同的时间内完成。这种资源投资根本无法扩展到未来。
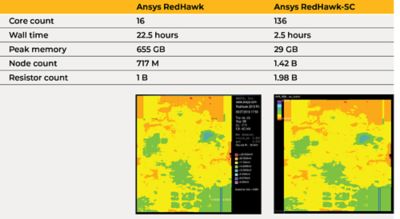
但与STA不同的是,这次Xilinx工程师能够将未修剪的数据集直接输入RedHawk-SC,后者构建在SeaScape之上,因此可以本地处理修剪。在实验中,该团队分析了一个中等大小的静态IR下降的位置和路由块(由于电阻在电力输送网络中损失的直流电压),比较了四核经典红鹰运行和16核红鹰- sc运行。在测试用例中,经典RedHawk的挂钟时间为57分钟,而RedHawk- sc的挂钟时间为18分钟,这是一个很好的附加比较基线。下一个比较测试了一个包含7800万个逻辑门的非常大的地点和路线区域——再次在两个工具中运行静态IR drop。经典的红鹰在单个主机上最多可达16个核,而红鹰- sc在LSF农场上轻松扩展到136个核。
由于RedHawk- sc将设计划分到如此多的机器或工作人员上,因此实验只需要每个工作人员29 GB的峰值内存,而经典的RedHawk则需要655 GB的峰值内存。与挂钟时间相比,RedHawk- sc的分布式计算仅在2.5小时内就完成了静态分析,而经典的RedHawk需要22小时。
结果是在性能上有了显著的改进。RedHawk- sc能够实现更快的周转和分布式计算,并且它比经典的RedHawk具有更细的粒度。毫无疑问:这是EM/IR分析的未来。
ANSYS Path FX:芯片级互连延迟的弹性计算
除了传统的STA定时关闭之外,Xilinx还有一个称为定时捕获的内部过程,这是特定于其全可编程架构的,由该公司的Vivado软件驱动。Vivado是为芯片编程的工具,它本身就像一个完整的实现流程。时序捕获不仅需要芯片的物理视图,还需要了解其点对点互连延迟。
因为在芯片编程时计算这些延迟是不切实际的,Xilinx在设计芯片时就预先计算了这些延迟,然后将延迟编程到Vivado中。因此,该工具已经意识到各个PVT角的互连时间,并在编程期间使用该时间来优化芯片。测量这些延迟的过程类似于传统STA中的关键路径定时分析。而不是整个设计的定时,定时捕获集中在Vivado概述的高度关键的互连路径的子集。
对于传统的STA工具,必须分别处理每个冲突路径。每个冲突都意味着更新计时的单独调用。即使是可以组合在一起的路径,这个过程也是耗时的。Xilinx希望在不牺牲准确性的情况下获得更好的吞吐量和并行性。
该团队转向Ansys Path FX进行关键路径时序分析,该分析可以同时计算整个芯片上的pin-to-pin延迟,即使是在冲突的路径上。Ansys Path FX通过对每个路径独立应用约束,然后将许多路径完全并行地分布在许多工人上来实现这一壮举。

Xilinx Versal是一种自适应计算加速平台(ACAP),是一种新的异构计算设备类别。
基于FX晶体管级仿真模型的延迟计算意味着没有精度损失。
这就是弹性计算发挥作用的地方:您可以将所有这些路径作为小作业分配给LSF(负载共享设施)场中的许多主机。
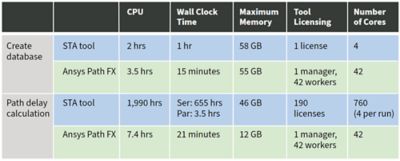
该团队在95,000条查询路径上进行了一项直接测试,比较Path FX与传统STA签收工具的性能。在测试中,在该公司可信的STA工具中,创建数据库需要一个小时的挂钟时间,但在Path FX中只需15分钟,内存占用相似(~55 GB)。
下一个阶段-路径延迟计算-是路径FX真正发光的地方。现有的STA工具需要190个单独的工具调用和近2,000个计算小时来完成所有路径的测量。挂钟时间很难精确地确定,因为团队使用了许多在半并行LSF配置中运行的工具调用。在完全并行运行所有190个工具调用的最佳(也是最昂贵的)情况下,挂钟的最佳时间将是3.5小时。更现实地说,可能接近100个小时。与此同时,Path FX的原生并行性允许它只用一个工具调用就能完成同样的任务,只需要7.4个计算小时。Path FX的挂钟时间是21分钟。
结果大大超出了设计团队的预期。通过使用传统STA工具的半并行方法,他们已经习惯了这项工作需要一周的时间。
Path FX的配置(一个许可证和42个工作人员)看起来比传统STA工具的190个许可证更具成本效益。
大、快、准
为了突破现代仿真瓶颈,Xilinx重新思考了其设计方法,并采用了使用Ansys工具的新方法。事实证明,这些工具可以在不牺牲计时和EM/IR分析精度的情况下,大大加快得到结果的时间。在此过程中,Xilinx采用了一种已经得到Twitter和亚马逊(Amazon)等公司支持的方法:大数据分析。
随着模拟数据规模越来越大,Xilinx利用Ansys SeaScape及其map-reduce分析来精简芯片规模的设计,以实现更快的时序分析。类似地,RedHawk-SC和Path FX使用智能修剪和分区,加上弹性大数据计算,将每个庞大的EM/IR或互连定时作业分解为一堆小块。在后端分析的各个方面,下一代硅都将依靠Ansys工具来实现。
看看Ansys可以为您做什么
看看Ansys可以为您做什么
联系我们
今天就联系我们
